ロボット、千葉ロッテマリーンズについていいかげんなことを書きます。
×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
Yahoo!コミックでバキSAGAが50ページ立ち読みできるみたいですよ.
・・・うん,これはある意味18禁ですね.
いつもの記事の本筋とは一切関係ない前置きはおいといて,今回はTimedWString型を使ってみます.
これも使ってるRTCを見たことないんだよな.
今回のサンプルはここからダウンロードできます.
今回作ったサンプルはTestWStringOutコンポーネントとTestWStringコンポーネントです.
まずTestWStringOutですが,1つのアウトポート(TimedWString型)を持っており,適当な文字列を出力します.
TestWStringは1つのインポート(TimedWString型)と4つのアウトポート(TimedString型)を持っています.
前回のサンプルと同じく,インポートから入力された文字列を名詞,動詞,形容詞,形容動詞に分けます.
そして,名詞なら名詞のなかからランダムで選択した名詞をアウトポートからTimedString型で出力します.
他も同じです.
・・・まあ,サンプルなので役に立つかどうかは考えてません.
なぜTimedString型かというと,OpenHRIの音声合成コンポーネントと接続するためです.
OpenHRIを解説してるサイトもあるようです.
以下のように接続できます.
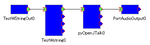
TestWStringコンポーネントのアウトポートを繋ぎかえることで名詞か動詞か形容詞か形容動詞を発声させるかを決めれます.
今回作成したRTCのコードを見ていきます.
TestWStringOutコンポーネントのonExecute関数は以下のようになってます.
m_out.data = L"(省略)" //データを書き込む
m_outOut.write(); //出力
return RTC::RTC_OK;
かなり簡単になりましたね.
続いてTestWStringコンポーネントのonExecute関数です.
setlocale( LC_ALL, "Japanese" );
if (m_inIn.isNew())
{
m_inIn.read(); //データ読み込み
std::wstring text = m_in.data; //データを取り出す
std::wstring noun;
std::wstring verb;
std::wstring adjective;
std::wstring na_adjective;
getnoun(text,text.length(),&noun,&verb,&adjective,&na_adjective); //名詞,動詞,形容詞,形容動詞に分けてランダムで選択したものをそれぞれnoun,verb,adjective,na_adjectiveに格納
std::wcout << text << std::endl; //入力データの表示
BYTE* nounUtf8; //8ビットに変換した名詞の文字列
UTF16utf8((BYTE*)noun.c_str(), &nounUtf8); //16ビットから8ビットに変換
m_noun.data = (char*)nounUtf8; //データを書き込む
m_nounOut.write(); //出力
・
・
・
以下略
となってます.
WStringを表示するときはstd::coutではなく,std::wcoutを使います.
OpenHRIはUTF-8でしか受け付けてくれないので,UTF-16から変換します.
コンフィグレーション・パラメータとかでUTF-8かShift-JISか選べたら便利だと思ったり思わなかったりですね.
今日はこのぐらいにしときます.
次回何やるかは未定です.
ExtendedDataTypes.idlとかInterfaceDataTypes.idl見ても,面白いデータ型はあるけど「これ絶対使わないだろ」ってのは見た感じないしなぁ.
コネクタの設定をいぢくってみるか,それともソースをいぢくってみるか,はたまたOpenRTM.NETに手を伸ばすか考え中です.

にほんブログ村のロボットのカテゴリから
全然人が来ない・・・

・・・うん,これはある意味18禁ですね.
いつもの記事の本筋とは一切関係ない前置きはおいといて,今回はTimedWString型を使ってみます.
これも使ってるRTCを見たことないんだよな.
今回のサンプルはここからダウンロードできます.
今回作ったサンプルはTestWStringOutコンポーネントとTestWStringコンポーネントです.
まずTestWStringOutですが,1つのアウトポート(TimedWString型)を持っており,適当な文字列を出力します.
TestWStringは1つのインポート(TimedWString型)と4つのアウトポート(TimedString型)を持っています.
前回のサンプルと同じく,インポートから入力された文字列を名詞,動詞,形容詞,形容動詞に分けます.
そして,名詞なら名詞のなかからランダムで選択した名詞をアウトポートからTimedString型で出力します.
他も同じです.
・・・まあ,サンプルなので役に立つかどうかは考えてません.
なぜTimedString型かというと,OpenHRIの音声合成コンポーネントと接続するためです.
OpenHRIを解説してるサイトもあるようです.
以下のように接続できます.
TestWStringコンポーネントのアウトポートを繋ぎかえることで名詞か動詞か形容詞か形容動詞を発声させるかを決めれます.
今回作成したRTCのコードを見ていきます.
TestWStringOutコンポーネントのonExecute関数は以下のようになってます.
m_out.data = L"(省略)" //データを書き込む
m_outOut.write(); //出力
return RTC::RTC_OK;
かなり簡単になりましたね.
続いてTestWStringコンポーネントのonExecute関数です.
setlocale( LC_ALL, "Japanese" );
if (m_inIn.isNew())
{
m_inIn.read(); //データ読み込み
std::wstring text = m_in.data; //データを取り出す
std::wstring noun;
std::wstring verb;
std::wstring adjective;
std::wstring na_adjective;
getnoun(text,text.length(),&noun,&verb,&adjective,&na_adjective); //名詞,動詞,形容詞,形容動詞に分けてランダムで選択したものをそれぞれnoun,verb,adjective,na_adjectiveに格納
std::wcout << text << std::endl; //入力データの表示
BYTE* nounUtf8; //8ビットに変換した名詞の文字列
UTF16utf8((BYTE*)noun.c_str(), &nounUtf8); //16ビットから8ビットに変換
m_noun.data = (char*)nounUtf8; //データを書き込む
m_nounOut.write(); //出力
・
・
・
以下略
となってます.
WStringを表示するときはstd::coutではなく,std::wcoutを使います.
OpenHRIはUTF-8でしか受け付けてくれないので,UTF-16から変換します.
コンフィグレーション・パラメータとかでUTF-8かShift-JISか選べたら便利だと思ったり思わなかったりですね.
今日はこのぐらいにしときます.
次回何やるかは未定です.
ExtendedDataTypes.idlとかInterfaceDataTypes.idl見ても,面白いデータ型はあるけど「これ絶対使わないだろ」ってのは見た感じないしなぁ.
コネクタの設定をいぢくってみるか,それともソースをいぢくってみるか,はたまたOpenRTM.NETに手を伸ばすか考え中です.
にほんブログ村のロボットのカテゴリから
全然人が来ない・・・
PR
この記事にコメントする